Moments of a Random Variable Explained
A while back we went over the idea of Variance and showed that it can been seen simply as the difference between squaring a Random Variable before computing its expectation and squaring its value after the expectation has been calculated.$$Var(X) = E[X^2] - E[X]^2$$
A questions that immediately comes to mind after this is "Why square the variable? Why not cube it? Or apply the sine function to it?"
Part of the answer to this lies in Jensen's Inequality. Before we can look at the inequality we have to first understand the idea of a convex function. In simple terms a convex function is just a function that is shaped like a valley. So for example \(x^4\) is a convex function from negative infinity to positive infinity and \(x^3\) is only convex for positive values and it become concave for negative ones (thanks to Elazar Newman for clarification around this).

Jensen's Inequality states that given a convex function \(g\) then $$E[g(X)] \geq g(E[X])$$
And since \(f(x) = x^2\) is a convex function this means that:$$E[X^2] \geq E[X]^2$$
Why does this matter? Well it means that because \(E[X^2]\) is always greater than or equal to \(E[X]^2\) that their difference can never be less than 0! This corresponds very well to our intuitive sense of what we mean by "variance", after all what would negative variance mean? It is also conviently the case that the only time \(E[X^2] = E[X]^2\) is when the Random Variable \(X\) is a constant (ie there is literally no variance).
Jensen's inequality provides with a sort of minimum viable reason for using \(X^2\). \(X^2\) can't be less then zero and increases with the degree to which the values of a Random Variable vary. In mathematics it is fairly common that something will be defined by a function merely becasue the function behaves the way we want it to. But it turns out there is an even deeper reason why we used squared and not another convex function.
Other measures of a distribution
There are a few other useful measurements of a probability distribution that we're going to look at that should help us to understand why we would choose \(x^2\). Before we dive into them let's review another way we can define variance. We used the definition \(Var(x) = E[X^2] - E[X]^2\) because it is very simple to read, it was useful in building out a Covariance and Correlation, and now it has made Variance's relationship to Jensen's Inequality very clear. In a previous post we demonstrated that Variance can also be defined as$$Var(X) = E[(X -\mu)^2]$$ It turns out that this definition will provide more insight as we explore Skewness and Kurtosis.
Skewness
Skewness defines how much a distribution is shifted in a certain direction. The mathematical definition of Skewness is $$\text{skewness} = E[(\frac{X -\mu}{\sigma})^3]$$ Where \(\sigma\) is our common definition of Standard Deviation \(\sigma = \sqrt{\text{Var(X)}}\).
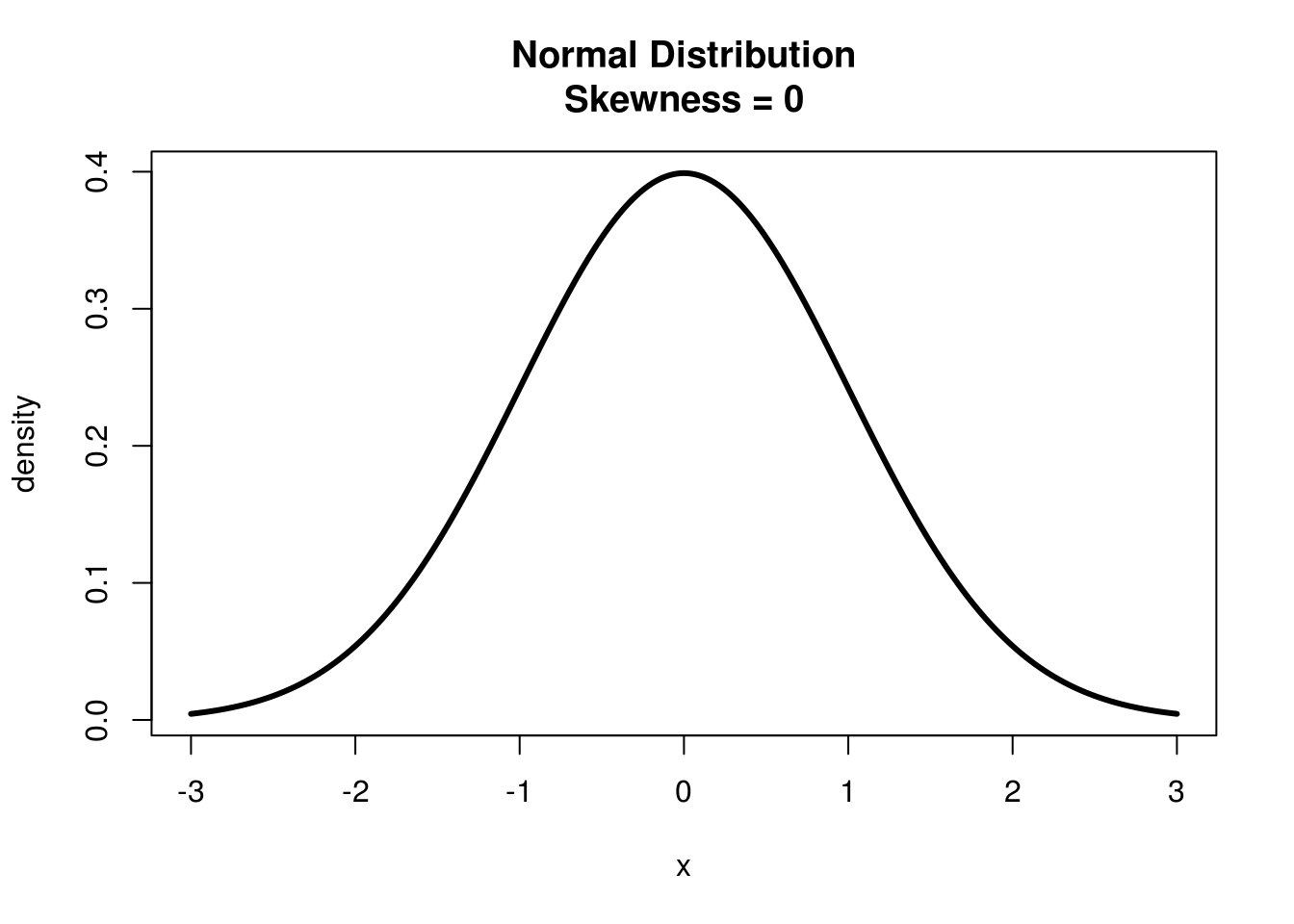
The Normal Distribution has a Skewness of 0, as we can clearly see it is equally distributed around each side.
However this is not true of the Log-Normal distribution. For the Log-Normal Distribution Skewness depends on \(\sigma\). For a Log-Normal Distribution with \(\mu = 0\) and \(\sigma = 1\) we have a skewness of about 6.2:

With a smaller \(\sigma = 0.5\) we see the Skewness decreases to about 1.8:

And if we increase the \(\sigma = 1.5\) the Skewness goes all the way up to 33.5!

A distribution like Beta(100,2) is skewed to the left and so has a Skewness of -1.4, the negative indicating that the it skews to the left rather than the right:

Kurtosis
Kurtosis measures how "pointy" a distribution is, and is defined as:$$\text{kurtosis} = \frac{E[(X-\mu)^4]}{(E[(X-\mu)^2])^2}$$ The Kurtosis of the Normal Distribution with \(\mu = 0\) and \(\sigma = 1\) is 3. Because of this the measure of Kurtosis is sometimes standardized by subtracting 3, this is refered to as the Excess Kurtosis. This way all other distributions can be easily compared with the Normal Distribution.
The Logistic Distribution has an Excess Kurtosis of 1.2 and the Uniform distribution has an Excess Kurtosis of -1.2. Below are all 3 plotted such that they have \(\mu = 0\) and \(\sigma = 1\).

One important thing to note is that Excess Kurtosis can be negative, as in the case of the Uniform Distribution, but Kurtosis in general cannot be.
What's the Trend here?
Now let's rewrite all of thee forumlas in a way that should make the commonality between all these different measurements really stand out:
$$\text{variance} = E[(X -\mu)^2]$$
$$\text{skewness} = E[(X - \mu)^3 \frac{1}{\sigma^3}]$$
$$\text{kurtosis} = E[(X - \mu)^4] \frac{1}{\sigma^4}$$
At it's core each of these function is the same form \(E[(X - \mu)^n]\) with the only difference being some form of normalization done by an additional term.
This general form describes what is refered to as a Moment. As we can see different Moments of a Random Variable measure very different properties. Going back to our original discussion of Random Variables we can view these different functions as simply machines that measure what happens when they are applied before and after calculating Expectation.
We can also see how Jensen's inequality comes into play. Variance and Kurtosis being the 2nd and 4th Moments and so defined by convex functions so they cannot be negative. However Skewness, being the 3rd moment, is not defined by a convex function and has meaningful negative values (negative indicating skewed towards the left as opposed to right).
Conclusion
We have convered some of the useful properties of squaring a variable that make it a good function for describing Variance. Not only does it behave as we would expect: cannot be negative, monotonically increases as intuitive notions of variance increase. But we have also shown that other functions measure different properties of probability distributions.
You might still not be completely satisfied with "why \(x^2\)", but we've made some pretty good progess. At some future point I'd like to explore the entire history of the idea of Variance so we can squash out any remaining mystery. Additionally I plan to dive deeper into Moments of a Random Variable, including looking at the Moment Generating Function.
If you enjoyed this post please subscribe to keep up to date and follow @willkurt!